


When working with data, structure is important. If all data is stored in one large table, it quickly becomes difficult to understand and manage. Even when there are several datasets, it can still be confusing to understand how the data relates to each other. Because of this, we need a way to map and organise these relationships.
Let’s look at an example dataset from the Atlanta Fire Rescue Department.
Here are the four datasets:
1. Fire Stations - This dataset contains information about each fire station.
2. Incident Types - This dataset lists the different types of incidents that can occur.
3. Incident Details - This dataset contains information about individual incidents, such as when and where they occurred and which station responded.
4. Targets - This dataset stores response time targets.

As we can see, fields from different datasets relate to each other in different ways, and not all data points have a strong relationship. Instead, data can be organised into smaller, logical groupings based on how the information connects.
Without this kind of organisation, it becomes difficult to see which data points belong together or how they relate across datasets.
This is where a schema becomes useful. A schema provides the structure used to organise data within a database, grouping related fields together so the information is easier to understand, manage and analyse, rather than existing as one large block of data.
Within a typical schema structure, data is often separated into fact tables and dimension tables.
What are fact tables and dimension tables?
The fact table stores the main events or records that we want to analyse. In this example, we want to focus on fire stations’ performance in response times. The fact table therefore contains information about each incident and the response to it.

These records describe what happened during each incident, but they often reference additional information stored elsewhere.
Dimension tables store this descriptive data that provides more context for the facts. They are linked to the fact table through keys, whereby a primary key uniquely identifies each record in a table, while a foreign key is used in another table to reference that record and create a relationship between the datasets.
For example:
- A Station ID (primary key) in the fact table links to the Fire Stations dimension table (as a foreign key), which contains descriptive information about each station such as country, state, city, latitude, longitude and zip code.
- An Incident Type Code (primary key) in the fact table links to the Incident Types dimension table (as a foreign key), which describes the type of incident.
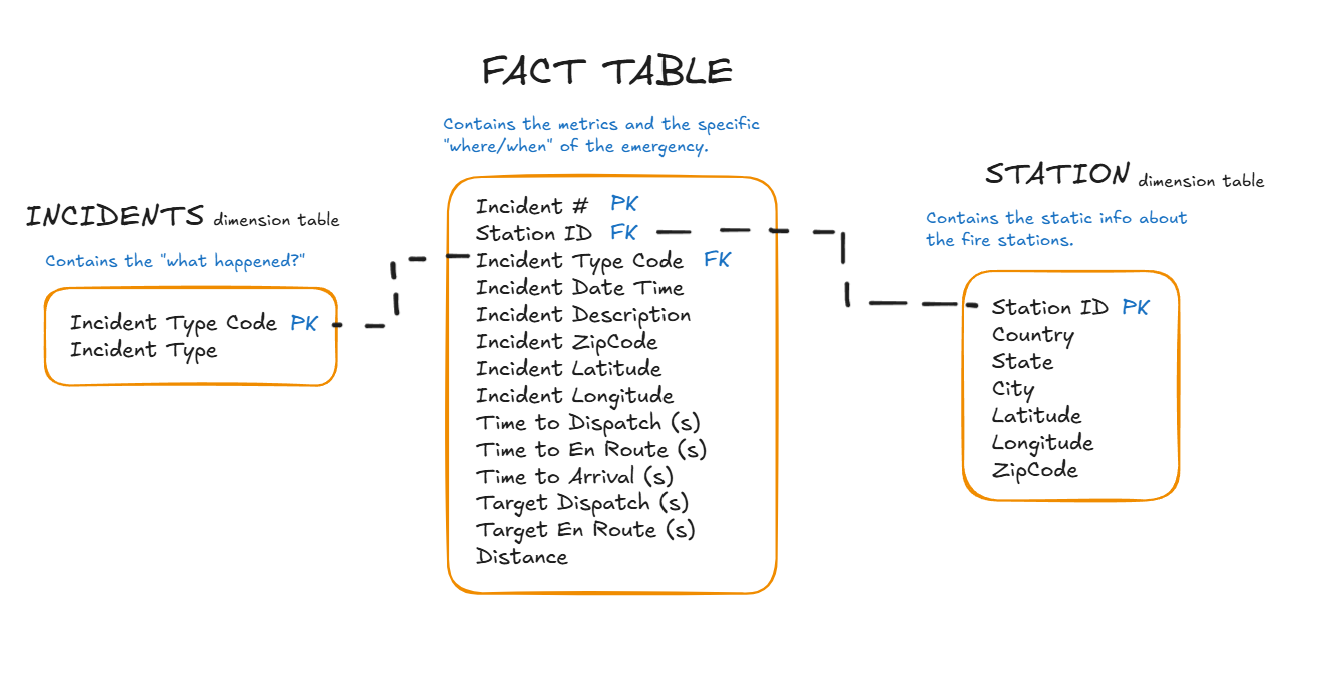
Therefore, the fact table only needs to store the Station ID and Incident Type Code to reference multiple related pieces of information stored in their respective dimension tables. This not only makes the database smaller and more efficient but also makes it easier to update or maintain the data, since changes only need to be made in one place.
When do you create a dimension table?
Not every field needs its own dimension. If there are only one or two attributes, separating them may not add much value.
For example, fields like Time to Dispatch, Time to En Route, and Time to Arrival may remain in the fact table because they are direct measurements of the incident event.
Dimension tables are most useful when there is a larger group of related attributes, such as station location details or incident classifications.
Using schemas in this way helps organise data more clearly, reduces duplication, and makes analysis easier. I’ve only just started using them, so it will be interesting to see how this approach performs as the data becomes more complex. I’ll be sure to share an update on my progress in the weeks to come!