


This is the second part of my RegEx blog-series, in which you'll learn to write your own RegEx!
If you've missed the first part, I recommend checking it out:
(here You can learn how a computer applies a RegEx to a given text)
Starting Simple
To visualize the RegEx and it's matches, I will use an online tool which I highly recommend to use
when you are a) trying to learn RegEx or b) testing and creating your own RegEx.
You can try it here: https://regexr.com/
Let's use this list of e-mail adresses as our example:
alex.miller@example.com, j.smith_89@workplace.com, casey.jordan@emailhost.com, andreaBaumann@webservice.com, support@business-solutions.org, user-name@.invalid-domain
Simplest RegEx:
A Substring you want to match as plain text.
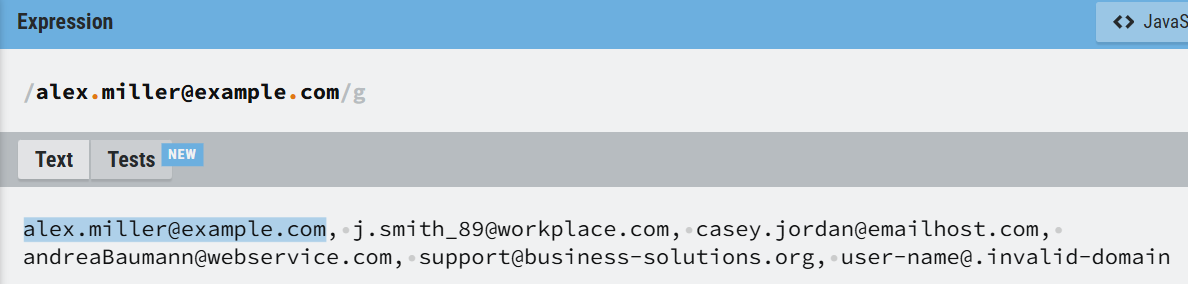
So, if I wanted to find Alex Millers e-mail adress in the list, the RegEx could just be "alex.miller@example.com":
Special Characters
Sure you can just search a given string, but RegEx shines where you have a lot of text and want to match parts with a specific structure.
A RegEx can contain placeholder for specific types of characters:
\d matches a digit, \w a word character, \s a seperator, . all except linebreak
Written uppercase (\D, \W, \S) they match the oppposite
You can also define your own set of characters by enclosing them in square brackets []:
[abcxyz] for example matches the characters x, y, z, a, b and c.
Occurences
We can define how often a character (or expression) shall occur, by adding one of the following after the character/expression:
* defines that the expression occurs zero or more times
+ defines that the expression occurs one or more times
{n} defines that the expression occurs n times
\w* matches a string of word characters with length zero or more.
\s+ matches a string of seperators with length one or more.
.{3} matches a string of characters (excluding line break) with length three.
Matching .com Mailadresses
With this knowledge we can decipher the RegEx from my previous Blog about Regex:

We'll break it down to smaller parts and understand them first:
[\w.]+:
A positive amount of word-characters and '.' mixed.
The square braces [] define a set of characters to match. \w for word-characters and '.' for the literal character '.' (in square braces it loses it's meaning as a placeholder).
The plus + defines we are looking for a string with one or more occurences of the characters defined in the set.
@:
Just the character '@' once.
\w+:
A positive amount of word-characters.
\.com:
The string ".com" (because we are outside square brackets, we have to escape '.' with '\' to define the literal '.' character and not it's meaning as a placeholder).
And in combination this is roughly how an Emailadress is structured.
Let's check, if we can match all .com adresses from our list with this RegEx:
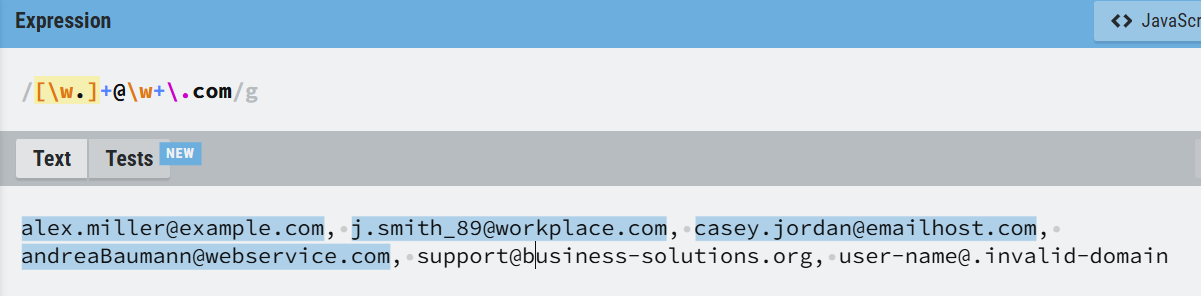
Success!
Now this expression is not perfect (we didn't consider '-' for example), but hopefully it enlightened your understanding of the structure of a RegEx and what some special characters mean.
There is much more to learn and if you are interested, just go to regexr.com and try some expressions yourself or visit this Regex cheat sheet to stumble through a list of special characters and overall RegEx syntax.
I might add using RegEx in Tableau and Alteryx in the near future, but for now this it from me about RegEx.