


Every project begins with the task of charting a clear path forward, carefully considering what is required to achieve the desired outcomes and meet all objectives. A thoughtful strategy weaves together the essential steps with the necessary resources to support them, from identifying reliable data sources to selecting the right platforms and preparing the required environments. By attending to these details early, this foundational phase not only guides the project’s direction but also shapes the approach to its execution, setting the stage for smoother progress and more informed decision-making.
Every project shapes its workflow according to its scope and timeline, and this short, four-day pipeline project is no exception. The journey begins by extracting data from the Mailchimp API and carefully loading it into an S3 bucket using Python, laying the groundwork for everything that follows. From there, the data is transferred into Snowflake through a pipeline, where it is transformed into structured tables using dbt, following a Stage, Intermediate, and Mart layout inspired by the medallion model. The final chapter of the process orchestrates the entire pipeline, ensuring that each step runs automatically on a set schedule, thereby transforming what began as a series of individual tasks into a seamless and reliable workflow.
Even with careful planning and preparation, projects rarely go exactly as expected. This is far from catastrophic; a skilled consultant adapts their approach to accommodate unexpected challenges, including sudden changes, unforeseen bugs, and tasks that take longer than anticipated. Flexibility and responsiveness become just as important as the original plan, turning obstacles into opportunities to refine the process and keep the project moving forward.
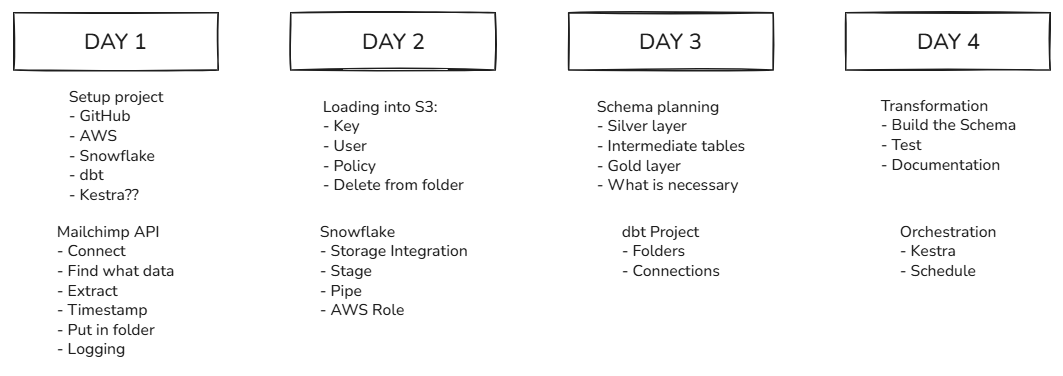
The goal on the first day was to set up all environments on the platforms to streamline integration, while also creating a simple Python script to call the API and investigating the documentation to better understand the structure and content of the data.
Since a dbt project initialises a folder structure in the GitHub repository, and the same repo is used to store Python scripts, it made sense to create the repo, set up the dbt project, and initialise the folder structure from the start. Once everything was pushed to the main branch and merged, the repository could be cloned into Visual Studio, providing a ready environment for the Python coding to begin.
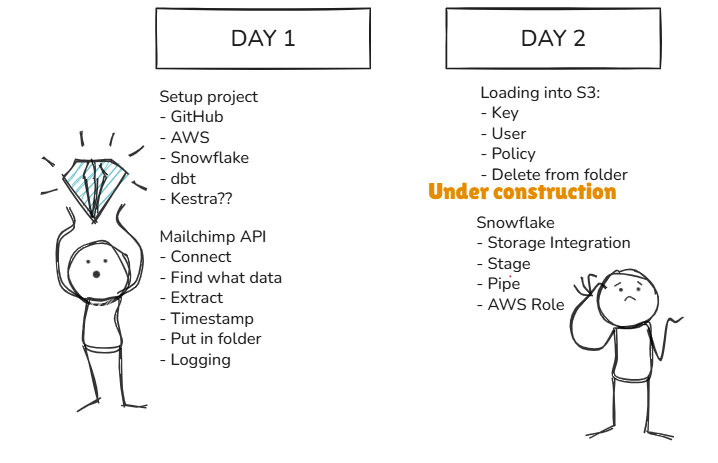
The first day unfolded without interruption, but the second day introduced the first signs of trouble as the connection between Snowflake and S3 began to resist cooperation. The plan was straightforward: a Python script would load the JSON files into an S3 bucket, clear them from the local environment, and allow a Snowflake pipe to pull the data into a table. What appeared simple in concept became far more intricate in practice.
For the Python script to communicate with S3, an IAM user, an appropriate policy, and the corresponding access keys were required. These keys needed to be stored locally in a configuration file kept outside the GitHub repository, preserving security while enabling programmatic access. On the other side of the workflow, establishing communication from S3 to Snowflake demanded a storage integration in Snowflake and a dedicated role in S3. This role relied on a trusted policy and an ARN to establish a secure, verifiable link between the two platforms.
The main complication surfaced when Snowflake repeatedly reported that it did not have access to the S3 bucket. The key policy, access policy, and trusted relationship were all reviewed and appeared to be configured correctly, yet the error persisted. Hours of research, discussion, and debugging gradually revealed an unexpected possibility: successful integration may require not only matching regions between Snowflake and S3, but also compatible account types. Early indications suggested that an AWS enterprise account might not connect smoothly to a Snowflake trial account, although no definitive documentation was found to confirm or refute this behaviour. The lack of clarity added another layer of complexity to an already puzzling challenge.
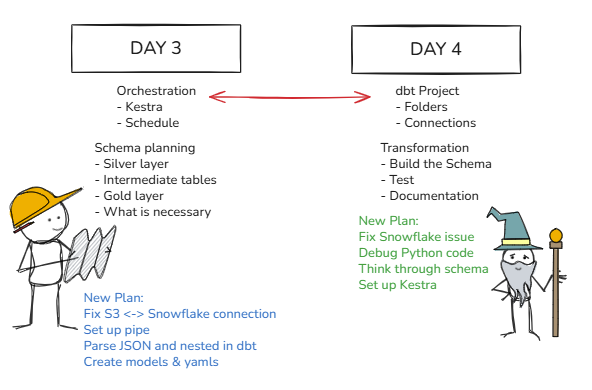
By the end of the day, the solution emerged in the form of a trial S3 account. Recreating the necessary keys, policies, storage integrations, and pipes within this new environment finally provided a configuration that worked. With the revised setup in place, the connection succeeded, and the data began flowing into the Snowflake table as intended.
With the underlying issue finally uncovered and resolved, the timeline required adjustment to compensate for the time lost. Days three and four shifted focus, beginning with an emphasis on transformation work in dbt. The aim for day three was to produce a functioning dbt project that parsed the JSON structure and its nested elements into separate, well-defined models. Achieving this would create the foundation needed for day four, which centred on designing a proper schema, building the dimension and fact tables, and configuring Kestra as the orchestration tool responsible for scheduling the workflow. During this stage, the dbt models and sources also required tests and freshness checks to verify that the ingested data behaved as expected.
Although unexpected setbacks can introduce pressure, projects that veer off course also serve as reminders of the adaptability required in consulting work. Shifting circumstances often demand revised goals, adjusted timelines, and a flexible mindset. In moments of difficulty, it is helpful to recognise that setbacks are a normal part of complex projects, to seek support from colleagues when obstacles become difficult to untangle, and to maintain patience and perspective as solutions take shape. These experiences not only strengthen technical skills but also build resilience, ultimately contributing to more confident problem-solving in future engagements.