


To read a more detailed account of the first week, check out the previous blog. In summary, the first week focused on the fundamentals of data engineering, providing a hands-on introduction to the stages of a data pipeline and how they interact to support evolving business needs. Key concepts included extraction, loading, orchestration, transformation, and governance, with an emphasis on the continuous cycle of reviewing, improving, and adapting pipelines. CI/CD principles were also introduced to demonstrate how pipelines can be maintained and scaled efficiently. Practical exercises explored various approaches to data extraction, highlighting both automated methods (using Airbyte) and scripted methods (using Python).

Building on that foundation, week two shifted focus to loading and orchestrating the data, with a brief introduction to transformation as the pipeline moved closer to producing analysis-ready datasets. The week included two projects, which are detailed in this blog.
What the Week Covered
Loading
Before diving into the comparison between loading data with Airbyte (a no-code tool) and a Python script, it’s important to outline what the loading process should involve. When working with Python code stored in a public GitHub repository, data security becomes a critical consideration - especially when handling sensitive information. To prevent any raw JSON files from being exposed, the Python script was designed to delete the extracted files immediately after they were uploaded to the S3 bucket. This ensured that no data could be accidentally committed to the repository. In addition, the data directory and relevant file types were added to the .gitignore file to provide an extra layer of protection.
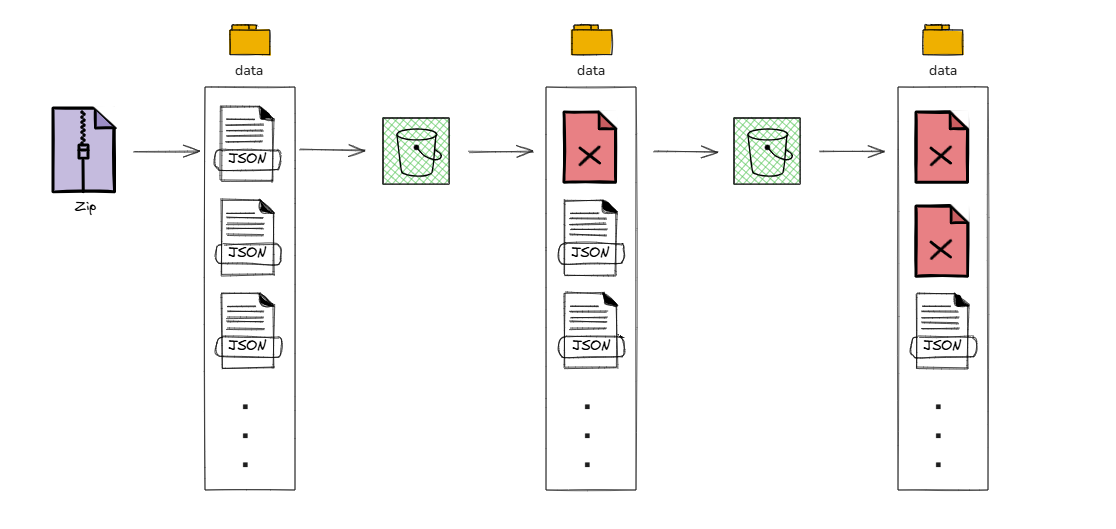
- Airbyte & S3
The setup for connecting Airbyte to S3 followed a similar process to connecting Airbyte to Amplitude. The main difference was that S3 served as the destination, while Amplitude functioned as the source. During configuration, S3 access keys were required to authorise the connection, and a sync schedule could be defined to control how frequently data was loaded into the bucket.
- Python & S3
A lightweight Python script was used to securely move the exported Amplitude JSON files into Amazon S3. The script loaded AWS credentials from environment variables, created an S3 client, and scanned a local data directory for all JSON files. Each file was uploaded into a dedicated S3 path, and upon successful upload, the local copy was immediately deleted. This ensured that sensitive raw data was never accidentally committed to the public GitHub repository and that the workspace remained clean after each run.
Orchestration
Several other steps in the data lifecycle still needed to be added to the project, but before tackling the heavier work of transformation, the focus shifted to orchestration. Orchestration is the process of automating the steps in a data pipeline to ensure they run reliably and efficiently. A variety of tools are available to manage this automation.
Orchestration generally falls into two categories: scheduling and triggers. Scheduling executes tasks based on predefined time intervals, while triggers initiate processes in response to specific events or changes in the system. Understanding these methods is crucial for designing pipelines that run smoothly without requiring constant manual intervention.
- Windows Task Scheduler
The first orchestration tool explored was Windows Task Scheduler, a built-in program available on all Windows systems. As an established tool with a long history, it provided a reliable way to automate tasks, though setup could be somewhat tedious. Creating schedules in Windows Task Scheduler was straightforward, but managing them could be cumbersome. Setting up triggers proved to be much more complex, requiring careful configuration. This tool is particularly useful for users with limited budgets or for small, individual teams that do not require extensive collaboration. However, it has notable limitations: tasks can only run when the computer is powered on, execution is restricted to the user profile with administrative rights, and performance depends on the hardware's processing capacity.
- GitHub Actions
The next orchestration tool explored was GitHub Actions. Although a more recent addition to the GitHub environment, it offered significant flexibility in creating both schedules and triggers. There is a learning curve, as users need to write YAML code and be familiar with the GitHub environment. GitHub Actions make collaboration straightforward, but all resources required by the schedules or triggers need to reside within a repository. The free version also has limitations: server availability could affect execution, so an action scheduled to run every five minutes might be delayed if other users are queued for processing.
- Kestra
The final orchestration tool explored was Kestra, an online, open-source platform designed to manage and automate data workflows. Kestra offered a modern and highly flexible approach to orchestration, enabling the definition of complex flows and dependencies between tasks. Its interface and architecture made it well-suited for collaborative projects and scalable pipelines, providing more advanced functionality than simpler tools like Windows Task Scheduler.
Docker was used in conjunction with Kestra to ensure the workflow ran in a controlled and secure environment. This setup introduced some challenges, particularly in establishing the connection between Docker and Kestra. Additional difficulties arose in building the flow as discrete tasks and in ensuring that all required Python packages were correctly installed and connected to the script. Despite these hurdles, Kestra demonstrated the potential of open-source orchestration for complex, production-ready pipelines.
The Takeaway
Week two reinforced the importance of loading and orchestration in building efficient, secure, and scalable data pipelines. The comparison between Airbyte and Python highlighted the trade-off between automation and control, while exploring tools like Windows Task Scheduler, GitHub Actions, and Kestra demonstrated how orchestration solutions vary based on team size, technical expertise, and project complexity. Choosing the right approach ensures pipelines run reliably and can adapt to evolving business needs.
Curious to see the project in more detail? Check out the full code and workflow on my GitHub repository. For security reasons, access to the data is restricted and not available to anyone outside of The Information Lab.