



Day 2 of pipeline week and this time was more focused on setting up my s3 bucket to get the data I have extracted from the MailChimp API to load into it. From there I then set up my storage integrations and external stages which can allow what is being stored in the s3 bucket to be loaded into snowflake.
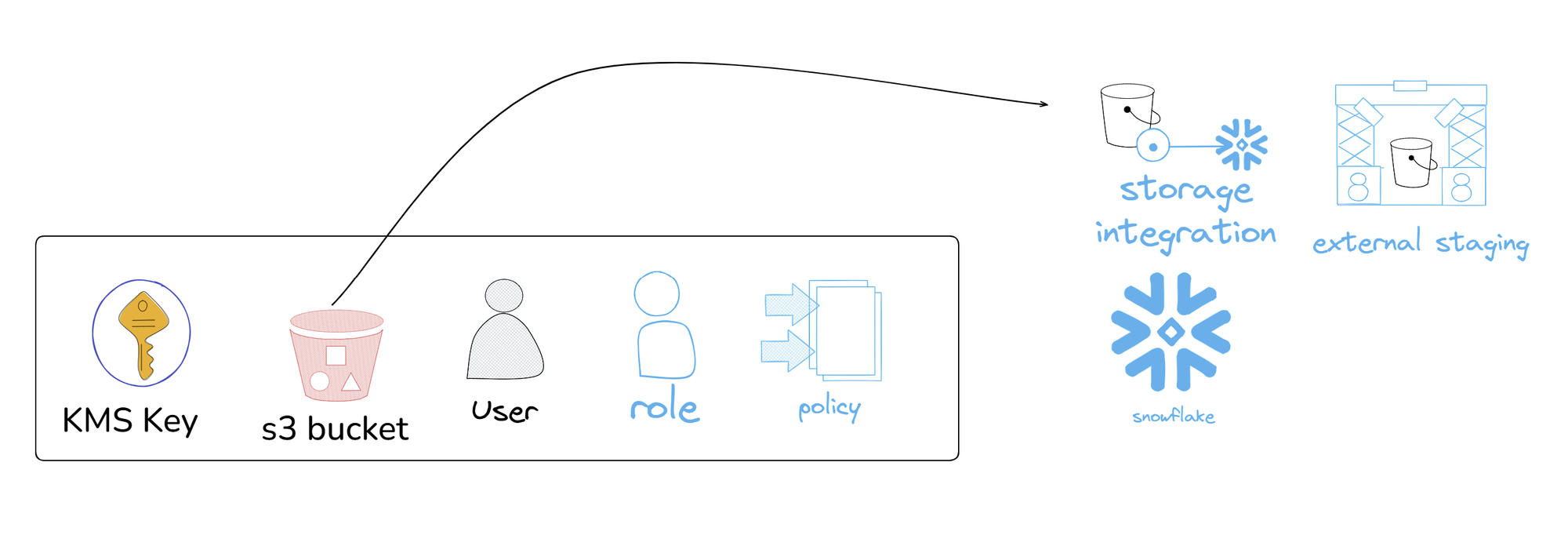
- First a KMS key was created so we can get its ARN (Amazon Resource Name).
- Then I created my s3 bucket and ensuring that public access is blocked and that it is encrypted using the ARN from the KMS key that was created.
- Created an IAM (Identity and Access Management) policy which will allow us to grant some privileges to our s3 bucket (e.g. loading/unloading data into snowflake)
- Created a user where I attached the policy that i just made and then created an access key from it and making note of the access key and secret key as they are essentially credentials for my bucket.
- An IAM role was made to grant access to my s3 bucket to be able to connect to snowflake.
That was the main steps taken to set everything up within the AWS side of things. I then went into snowflake and created a snowflake integration using the ARN from our s3 bucket and the online path of our bucket. Once that was set up I took the STORAGE_AWS_IAM_USER_ARN and an EXTERNAL_ID from it and put it inside our IAM role trust policy to allow users to be able to access objects within my bucket.
File formats, stages, and tables were made so that the data is ready to be loaded into snowflake .
Then I made and ran my python script to push the extracted data into my bucket and then inside snowflake I set up a snowpipe so that any new data that is loaded into my s3 bucket will automatically be loaded into the tables from the stage.