


When relational models were introduced
The Standard Query Language is often credited to a guy from Portland. Not Washington. The Isle in the county of Dorset in Southeast England.
That guy was Edgar F Codd. In 1970, while working for IBM in the States, he proposed the relational model as a logical approach to database management. He was working at IBM at the time and published “A Relational Model of Data for Large Shared Data Banks” in CACM. Of the paper, one of his teammates recalled:
At least back then, it seemed like a very badly written paper: some industrial motivation, and then right into the math.
- Irv Traiger, 1995 SQL Reunion
Despite the difficulty of his proposal, the work broke ground, won a Turing Award, and influenced many others from the US and UK to try their hand at creating their own query language.
Where SQL began
Codd stayed in the world of semantics, but made space for those who wanted to create syntax. He set up a symposium at IBM’s Yorktown labs where a team formed to work on a project called System R. By 1974, this produced Don Chamberlain and Ray Boyce’s presentation of SEQUEL: A Structured English Query Language.
Their proposed set of operations are the same clauses we use today:
- SELECT
- FROM
- WHERE
- GROUP BY
This initial language proposal also included familiar functions, such as SUM, COUNT, AVG, MAX, and MIN. And, there were basic data types like strings, numbers, and boolean values.
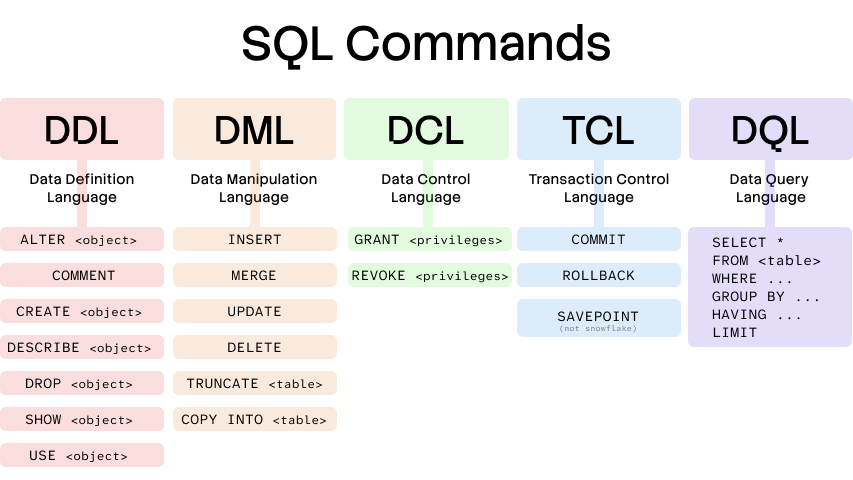
Codd later put forth 13 rules, known as Codd's 12 Rules because, of course, as a programmer, he numbered them zero through twelve. A recognizable rule is number 5 on sub-languages which suggests the following:
A relational system may support several languages and various modes of terminal use, such as:
1. Data definition.
2. View definition.
3. Data manipulation (interactive and by program).
4. Integrity constraints.
5. Authorization.
6. Transaction boundaries (begin, commit, and rollback).
This list is a near matches to the common sub-languages diagram found in so many beginner SQL tutorials.
How SQL impacts today
This history of SEQUEL, renamed as SQL, tells the story of problems we still face in database management. Namely, lowering software costs and allowing users to communicate with their data. In the pursuit of a solution, thousands of software companies have leveraged SQL and vied for developer attention in a billion dollar landscape.
How can we determine the value of each software in our stack?
As with most things in computer science, the answer is usually abstraction.
Today’s most popular database companies offer tools that are generally abstractions of foundational SQL sub-languages. Apache Iceberg tables handle transactions without users writing TCL. Data build tool (dbt) uses open-source software and Jinja templates to compile DDL and DML commands. Snowflake surfaces DCL permissions through a friendly user interface called the Trust Center. Now, LLMs can generate DQL from natural language.
Each layer removing friction from a different part of the stack.
Happy coding!