What is an API?
An API, which stands for Application Programming Interface, is a way for two or more computer programs to communicate with each other. You can think of it as a common language that developers use to bridge the gap between computer programs (software) that "speak" different languages. An API, therefore, translates between the programs by defining the kinds of requests that one program can make to another, the data formats that should be used, conventions to follow, etc.
In our work as analysts, our most common use case for APIs is data retrieval.
How do APIs work?
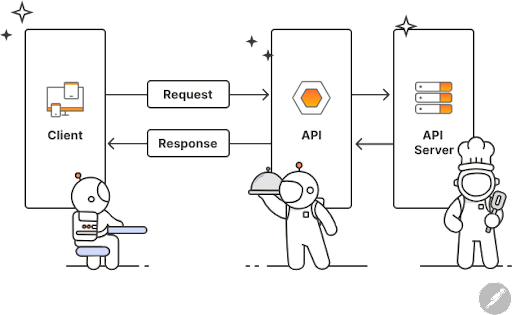
A user initiates a "request" to a API Server associated with a particular database. The request is sent to the API, which retrieves the data from the server, and returns to the user with a "response."
I've found this metaphor from Postman really useful in understanding how APIs work:
"... it can be useful to think of APIs like restaurants. In this metaphor, the customer is like the user, who tells the waiter what she wants. The waiter is like an API, receiving the customer's order and translating it into easy-to-follow instructions for the kitchen—sometimes using specific codes or abbreviations that the kitchen staff will recognize. The kitchen staff is like the API server because it creates the order according to the customer's specifications and gives it to the waiter, who then delivers it to the customer."
An Example
Say we want to obtain a list of all of the films made by Studio Ghibli. Thankfully, they have an API for everything related to Ghibli Studios here.
These would be the steps:
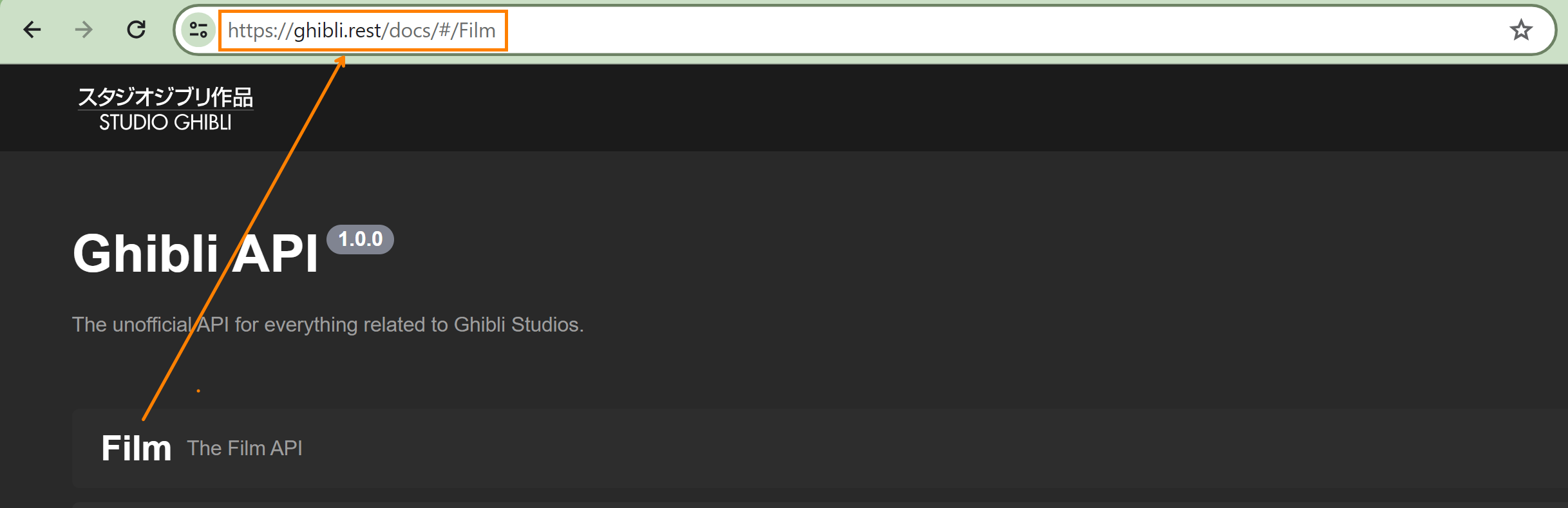
- Identify the Endpoint - this is the specific url link that determines the resource we are requesting. Since we want to pull data on films, we can find the endpoint url when we select the film category in the API documentation.
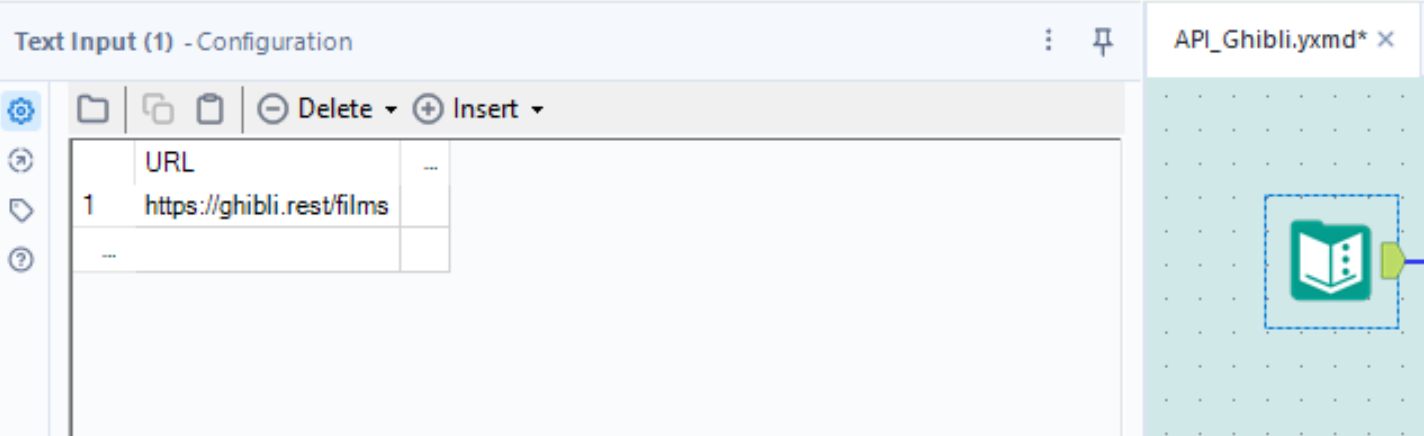
- Copy and paste the url into a Text Input tool on Alteryx Designer
- Use the Download tool to retrieve the data.
Make sure to:
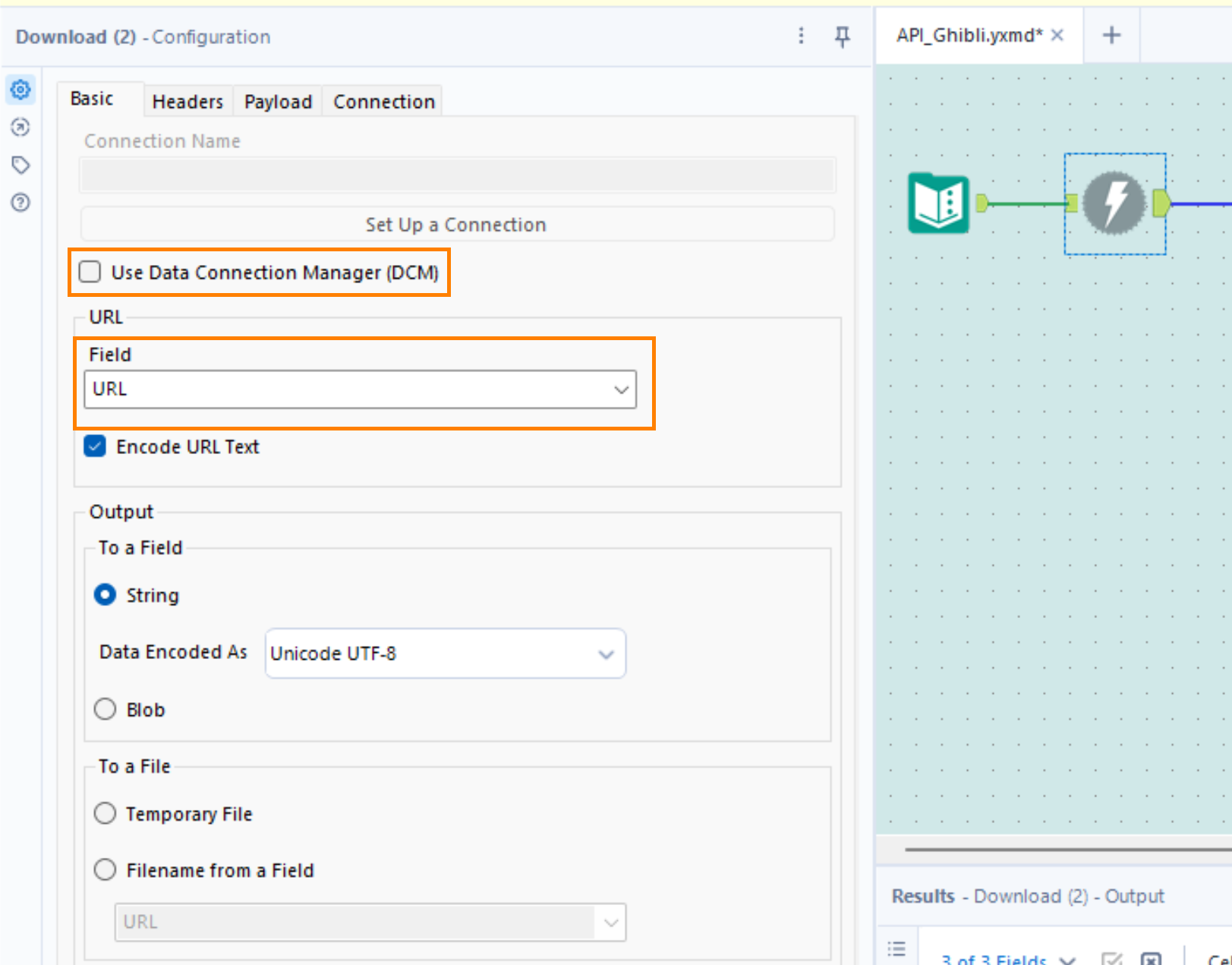
- Uncheck the 'Use Data Connection Manager (DCM)' box
- Select the right data Field from the Text input tool. In our case it's named URL
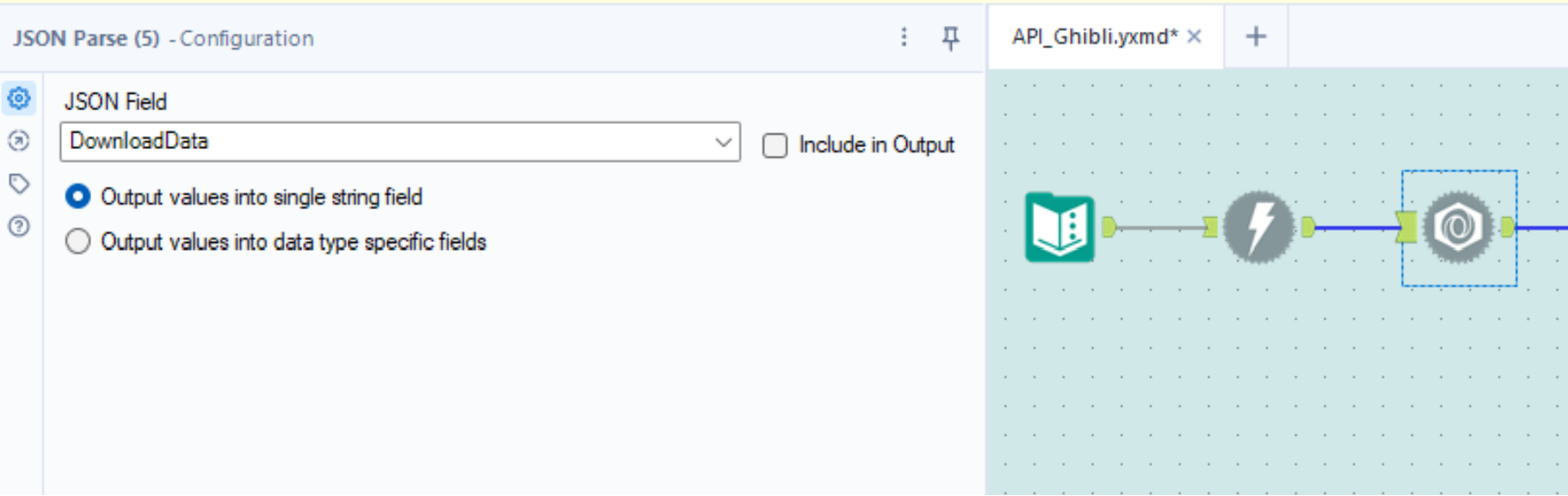
- Now, the next step is to transform the data from JSON into a format we can read more easily. JSON, which stands for Java Script Object Notation, is one of the formats data retrieved via APIS is often in. The other format is XML. To parse our data, we use the JSON Parse tool and configure it as follows:
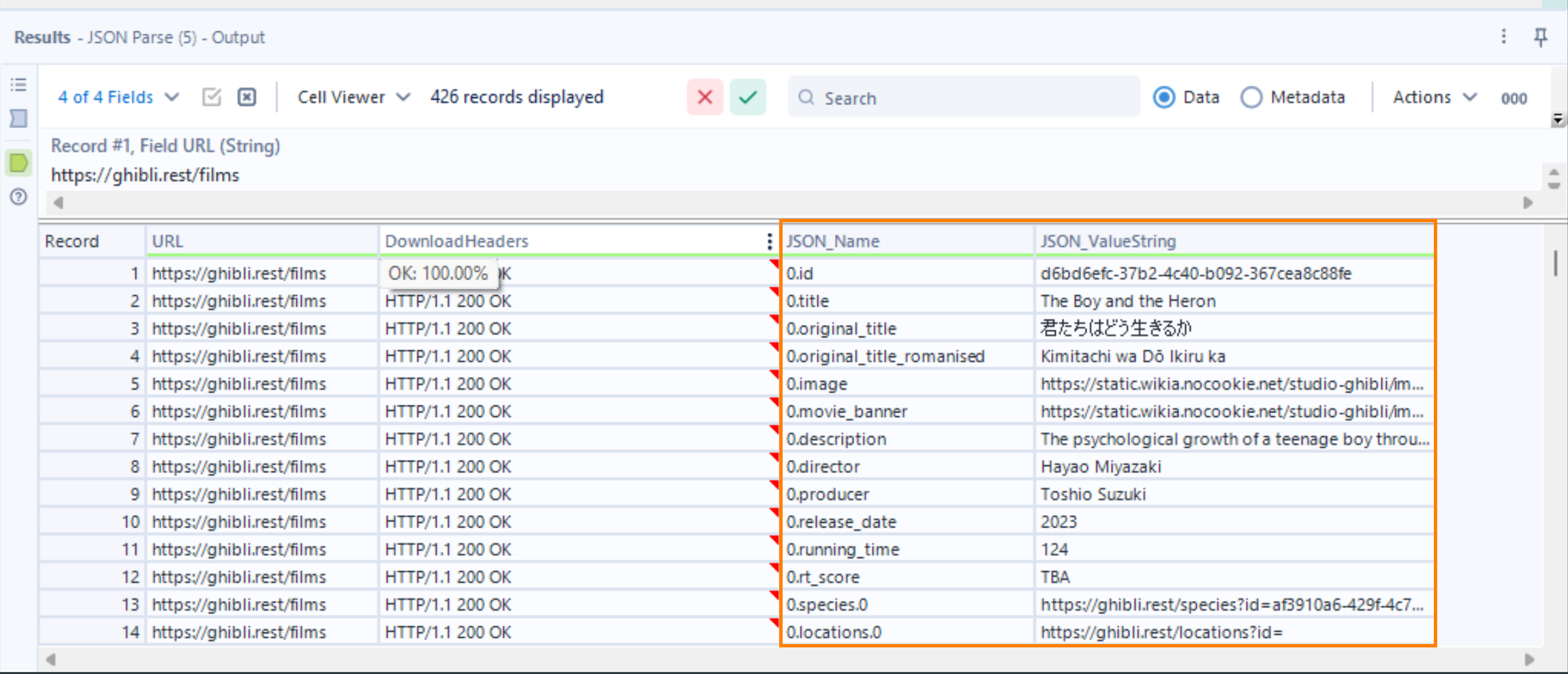
- After parsing, we obtain 2 fields that are of interest to us: i) JSON_Name, which corresponds to the column headers, and JSON_ValueString, which corresponds to the values for each of those headers.
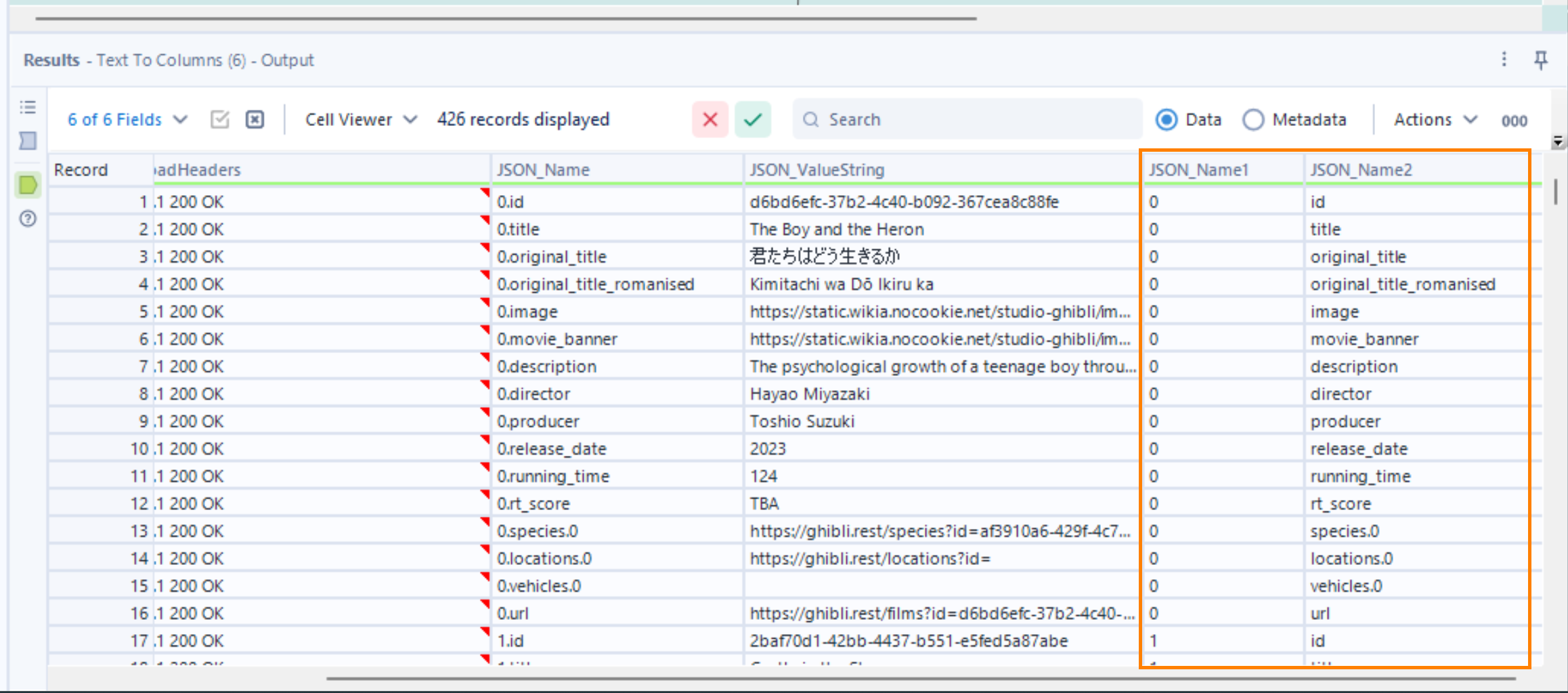
- The next step is to clean up those column headers a little. Notice that there's a '0.' before each header name. We want to get rid of those. So, we use a Text to Columns tool to split the field into 2 columns, with the period (.) as a delimiter. The result is a much cleaner column of headers: JSON_Name2 below. Here we can use the Select tool to get rid of all unnecessary fields (leaving only JSON_ValueString, JSON_Name1 and JSON_Name2) and to make our lives a little easier, rename the remaining fields to Value, Record_ID and Header respectively.
- Once we have the clean column headers, we want to identify which ones we need in order to create a table for the films. We can use the Filter tool to narrow down our data to only rows where the Header field does not contain the word 'people.' We could also filter to only rows where the Header field contains the word 'film,' but we would lose important film-related fields such as title, description, etc. This approach also allows us to come back later and use the same filter tool to create another table for people.
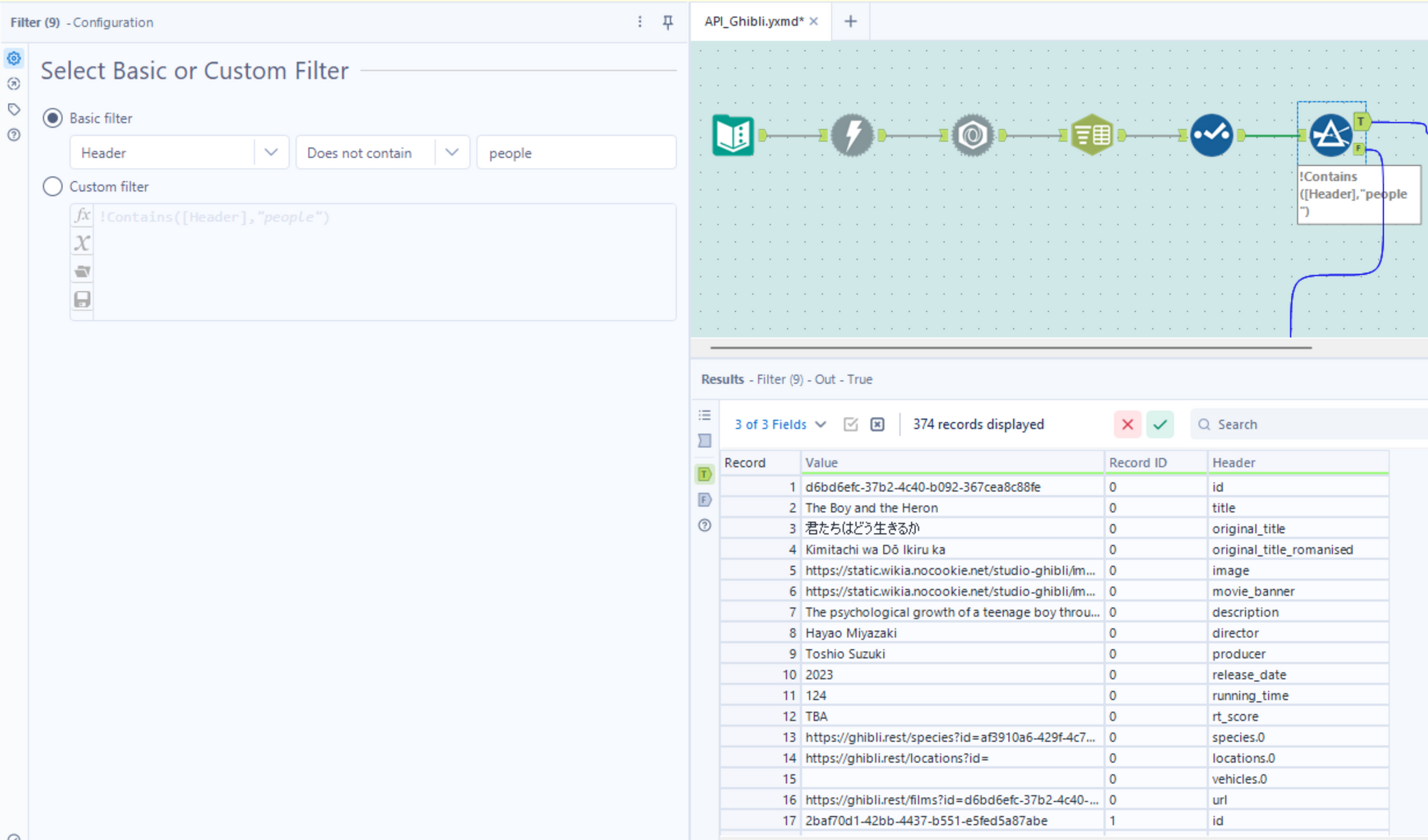
- Now the next step is to transform the table we now have such that we have a separate column for each of the fields in the Header column. Crosstab is the tool for this job. Configure it as follows:
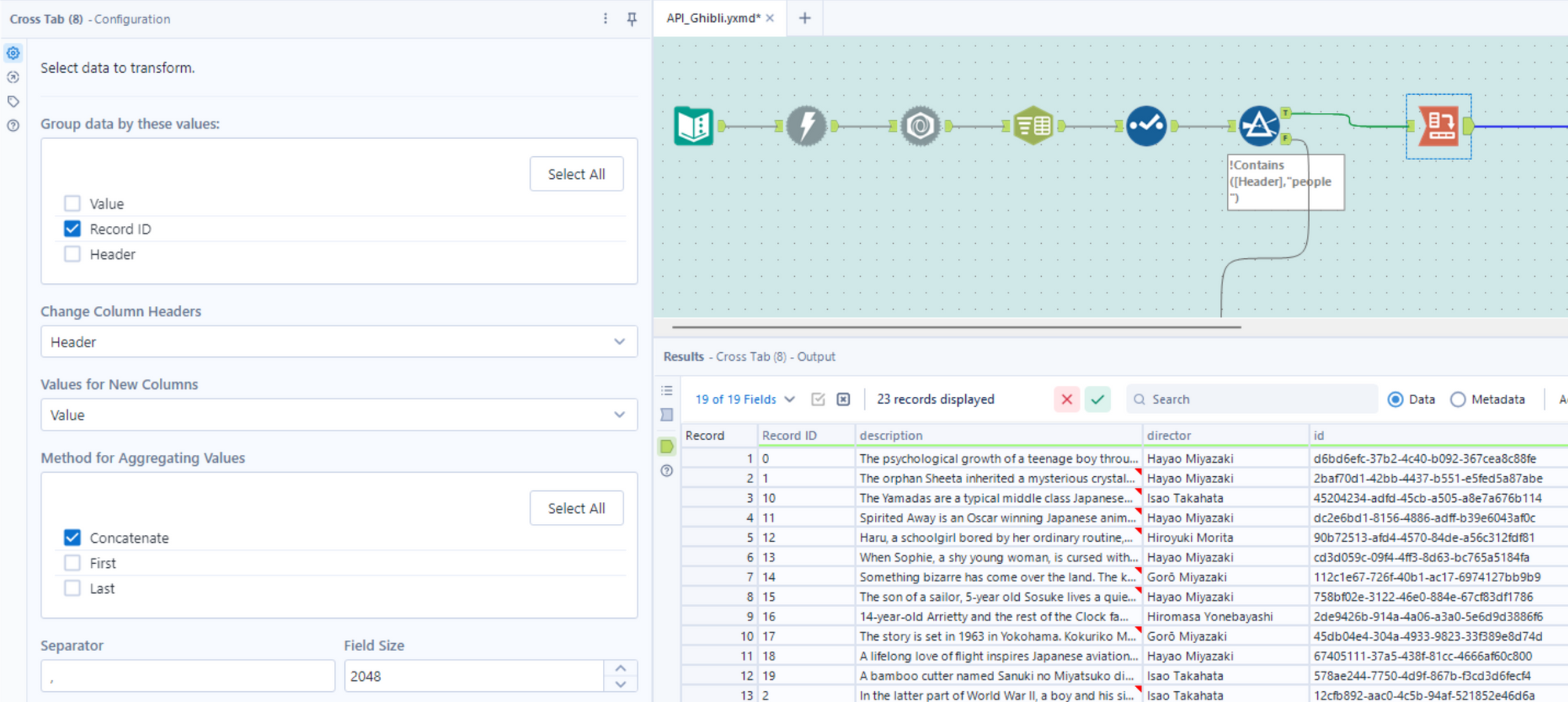
- The final step is to use the Select tool to re-order the fields as needed so we can see the film names more easily, and to get rid of any columns we don't need.
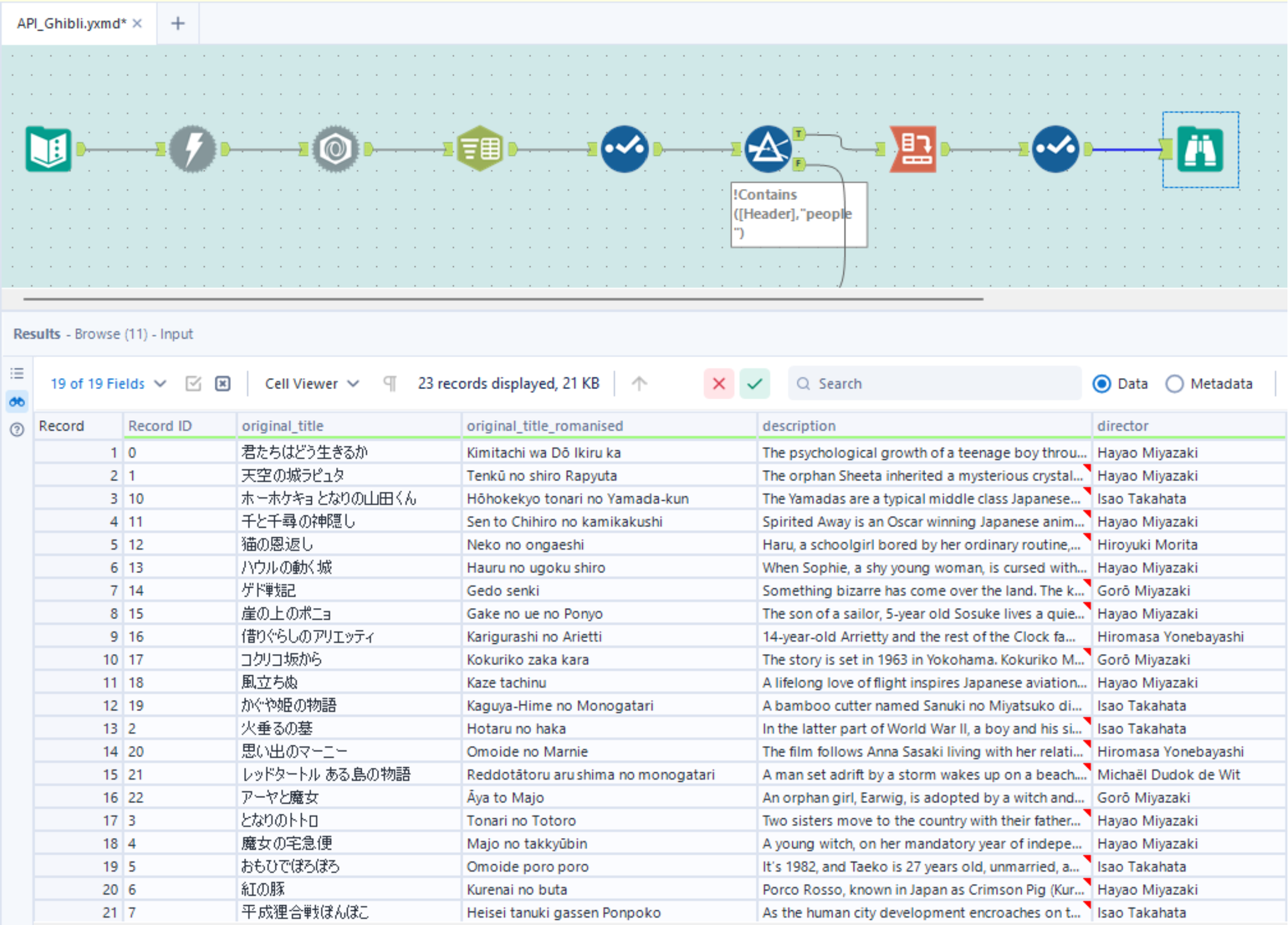
- And just like that, we have a table with all the films!