


What is SQL?
SQL stands for Structured Query Language. It is used to execute queries that retrieve data and insert, update, delete records, create and modify data. In SQL you can do most things that you do in Tableau Prep or Alteryx.
SQL follows a strict structure and will error if this structure is not followed. The structure is as follows:
- SELECT
- FROM
- WHERE
- GROUP BY
- HAVING
- ORDER BY
This is the basic structure in SQL - however, you do not need all these fields for a query, you could have a query as short as just the SELECT function!
Let me tell you about each of these functions below (with an example query at the end!)...
In the SELECT function, you write the names of the columns you want in your output. You can choose to bring in all the columns by using a * . Within this function you can also:
- Rename columns
- Use a calculation on a column to create a new column
In the FROM function, you tell SQL where (which table) to find the columns in. In the FROM function you can also:
- Give the table an alias to refer to within the code
- Join multiple tables together
- There are multiple join types: inner, full, left, right, and cross
The WHERE function is where you can filter what rows of data you bring in. There are multiple ways you can specify the criteria:
- BETWEEN x and y
- This function only works for numeric or date[time] type data
- Mathematical Operators
- =, != works with any data type
- >,< only with numeric or date[time] type data
- LIKE - i.e., column_name LIKE 'hello'
- Allows you to filter to cells that contain specific values and is case sesntivee
- Works with any data type
- You can also specify that the values only contain characters and has others around it using '%' to allow multiple characters or using '_' to allow one character
- i.e., column_name LIKE '%el%' this will bring back anything that contains 'el' but could have leading or trailing characters around it
- ILIKE - this is the same as LIKE except it is case insensitive
- IS NULL
- This allows you to find cells that are NULL
- You can also use NOT in front of any of these functions to return the opposite i.e., IS NOT NULL will return all rows where that column is not null
The GROUP BY function allows you to aggregate your data in teh SELECT function. If you wanted to get the SUM of a column, you would write SUM(column_name) in teh SELECT tool adn specify which column(s) you want to group this aggregation by in the GROUP BY function. You have to group by all the columns that you have selected.
So more easily you can GROUP BY ALL which aggregates by all the columns you bring through in teh SELECT tool. You can alos GROUP BY the order you've listed your columsn in teh select tool i.e., 1,2,3, etc.
The HAVING funciton is basically the same as the WHERE function, except it is fro an aggregated field - i.e., so you can filter by SUM(column_name)<10
Lastly, the ORDER BY function allos you to sort your data by a column(s). Simply write ORDER BY column_name ASC/DESC.
Let us put this all together! For this example I will use fields from Tableau's sample dataset Superstore and just write out what your code would look like.
To understand my example, you need to know that I have multiple tables in a schema (a schema shows how multiple tables relate to each other). See the image below for the schema.
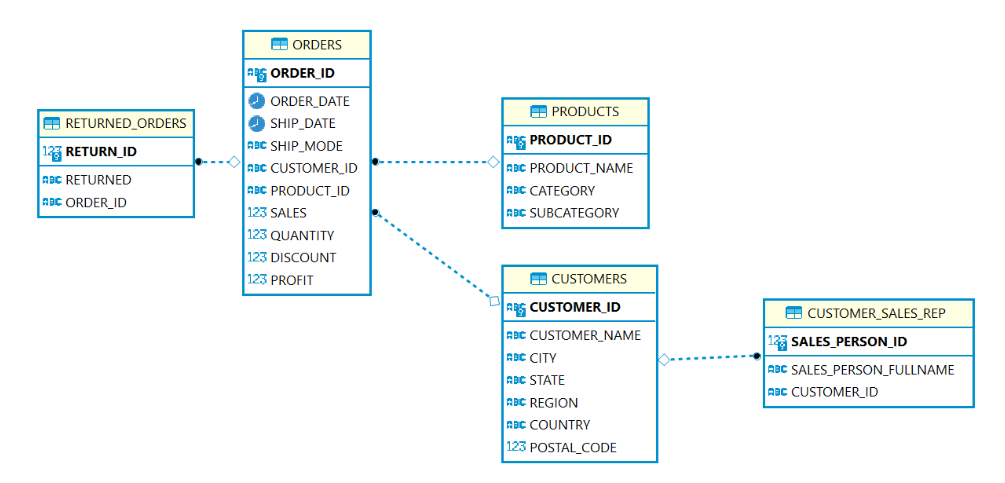
The example query is below and I will run you through each part.

Here, I am selecting the customer name to be in the results as well as the sum of sales renamed as 'Total_Sales' and the number of customers in a column called 'Order_Count'. The O in front of customer_id specifies that I want the customer_id from the Orders table. If a field appears in more than one table then you must specify which table you want to draw from otherwise an error will occur.
In the FROM function, I have specified I want to draw from the 'orders' table and want to use an alias of 'O' when referring to this table in the code. This is why when I explained above I put an O in front of customer_id to specify the table (If I hadn't added an alias, I would specify the table to draw the column from with the table name i.e., orders.customer_name).
Within the FROM I have done an INNER JOIN, where I have specified that I want to join the customers table (with an alias of 'C') to the orders table. This is where the schema comes in handy. We can see from the schema that the customer table relates to the orders table on customer_id. This is what I hav done in the join, I have told SQL how to relate the tables together, specifying the columns alongside their table ('O.customer_id = C.customer_id').
I have filtered using the WHERE function to only include customers that have an 'm' in their name. I have used the '%' to indicate that this could have multiple characters before or after it.
Next in the structure is the GROUP BY. Here we need a group by as we have aggregates in our SELECT. However, if there were no aggregate columns in our SELECT a GROUP BY would not be necessary. Here I have told SQL to GROUP BY the customer_name column - this will aggregate the values to have a row for each distinct customer name. However, it would also do the same thing if I grouped by ALL.
As explained above, the HAVING function allows you to filter using an aggregate column. Here I filter by the total sales (sum of sales), showing rows where this is above 10,000.
Lastly, I have used the ORDER BY function to show my results from highest to lowest total sales.