


Today marked my first experience with dbt (Data Build Tool). While I’m still getting familiar with the software, I’ve already found several aspects of its data transformation process to be quite intuitive. One feature I particularly appreciate is dbt’s approach to managing data sources. In this blog, I’ll walk you through how to call data sources in dbt and explain why I find this approach so beneficial.
Data Sources
Data sources refer to raw data files stored in a data warehouse. Traditionally, in SQL, you reference a data source by calling the table it resides in (e.g., database.table_name). However, in dbt, you can use the source function to reference data sources instead. This approach offers several benefits:
- The source can be attributed to multiple queries
- The source can be visualised clearly in dbt's lineage graph
- There are built in functions that can also check how recently the table has been updated
Application in dbt
Data sources can be configured in a YML file within a dbt workspace. While completing the fundamentals course I configured the following data source:
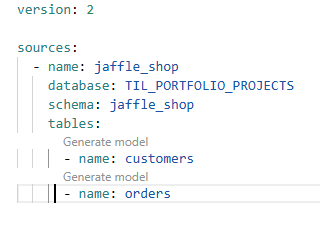
- name: jaffle_shop – The name of the source. This is an arbitrary name you assign to the source to make it easier to refer to later in your dbt project.
- database: TIL_PORTFOLIO_PROJECTS – The database where the source tables are located.
- schema: jaffle_shop – The schema within the specified database where the source tables are stored.
- tables: – This section lists the tables that belong to the defined source. Here, two tables, 'customers' and 'orders', are defined as part of the `jaffle_shop' source.
Referencing Sources
Once sources have been configured they can be used in future queries. This can be done using the ref function, which can be used as opposed to simply calling a table name.

This is advantageous because it can be applied to any query using that data source. If a future name change is made to the TIL_PORTFOLIO_PROJECTS database then instead of retyping this in every query, you can simply change the database name in the source.yml file.
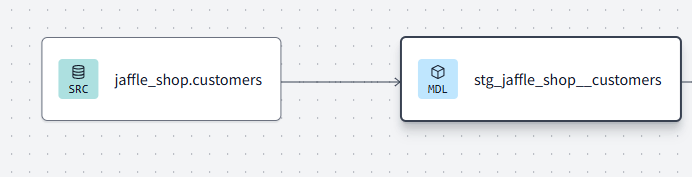
Using the ref function also builds a dbt lineage, showing the hierarchy and direction of travel of your data pipeline.
Data Freshness
The last feature I learnt about in relation to data sources in dbt is the ability to monitor how recently updated your raw data is.
This can be achieved be reconfiguring the data source YML file and adding the keys 'loaded_at_field' and 'freshness'.
loaded_at_field - Refers to a column in the raw data table that states a rows last updated date.
freshness - Helps an engineer define which time periods to throw a warning or error the whole process.
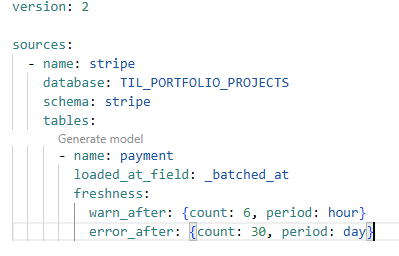
In the example above, if the field 'batched_at' has a latest value over 6 hours old, a warning message will appear when the workspace is run. If the field has a value over 30 days old then the whole process will error.
I hope this blog has helped to show you the effectiveness of data sources in dbt. If you would like to get hands on and learn this yourself, then you can follow the same course as me here: https://learn.getdbt.com/courses/dbt-fundamentals.