


Organising a dbt Project: Best Practices
When working with dbt, effective project organisation is key to ensuring maintainability, scalability, and collaboration. A well-organised dbt project not only simplifies debugging but also enhances readability. Here are some best practices to help you structure your dbt project effectively, covering folder organisation, YAML files, and naming conventions.
Folder Structure and Naming Conventions
The default folder structure of a dbt project is designed to provide clarity and ease of navigation. You can adapt it to fit your team's workflow, but a common structure includes the following:
- Models
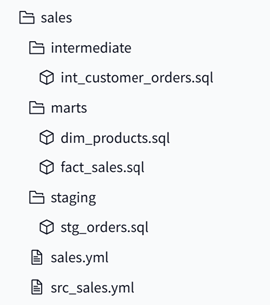
- Organise models by functional area or domain, e.g., sales, marketing, finance.
- Use subfolders for logical grouping within these areas, such as staging, intermediate, and marts.
- staging: Models which connect to sources and contain nothing more than simple transformations such as renaming fields and changing data types. Prefix files with stg_ (e.g., stg_orders.sql).
- intermediate: Models which connect to your staging models and provide business logic and transformations between staging and marts. Prefix files with int_ (e.g., int_customer_orders.sql).
- marts: Models which connect to intermediate models and finalise datasets to be used in analytics and reporting. Prefix files with dim_ (dimensions) or fact_ (facts), e.g., dim_products.sql and fact_sales.sql.
- Macros
- Store reusable SQL snippets in the macros/ folder. Group related macros into subfolders when necessary and use descriptive snake_case names (e.g., calculate_growth_rate).
- Seeds
- Place CSV files containing static or reference data in the seeds/ folder.
- Snapshots
- Use the snapshots/ folder to store snapshot configurations for historical data tracking.
- Analyses
- Store one-off or exploratory queries in the analyses/ folder.
- Tests
- Use the tests/ folder to store custom tests for data quality.
YAML Files
YAML files in dbt are essential for defining configurations, metadata and documentation. These files define models, sources, columns, and tests to ensure consistency and enforce data quality. Each project should include:
- DBT Project YAML (dbt_project.yml)
- The root configuration file for your dbt project – when we say project here we mean the dbt Project defined in your Profile settings. Working in a data mesh environment you may have multiple projects but generally,, you’ll be working within one. Within this project you may have variousModels can be generated directly from the source YAML, listing all the available fields, by clicking the Generate Model prompt. folders within your models folder but each one will be configured by the dbt_project.yml unless configured elsewhere.
- Schema YAML Files
- Define models, columns, and tests. Name them to match their respective model folders (e.g., models/sales/sales.yml).
- Add documentation at a model level as well as for individual columns.
- Source YAML Files
- Use these files to define sources and associated tests on sources (raw data). Consistently name them using the src_ prefix (e.g., src_sales.yml).
- Models can be generated directly from within the sources YAML listing all the available fields by clicking the Generate Model prompt.
By following these guidelines, your dbt project will be well-organised, maintainable, and scalable, enabling your team to focus on delivering actionable insights efficiently.