


Yesterday I was building a dimension staging table in dbt Cloud. I anticipated that the contents of the table will change overtime, so my original plan was to implement an incremental strategy. But, I also wanted a way to keep track of the table's history. To achieve both objectives, I built my staging table off a snapshot of the table in order to create a Slowly Changing Type 2 (SCD 2) table.
Slowly Changing Type 2 Tables
An SCD 2 table is a method in data warehousing that preserves the complete history of changes to dimension data by creating a new row for each change, rather than overwriting the existing one.
Let's say we have a table of names and street addresses.
| First Name | Last Name | Street Address |
| John | Doe | 123 Sunset Blvd |
| Jane | Doe | 145 Princeton Cir |
If any of the addresses get updated, we may want to preserve the history depending on our business needs. By creating an SCD 2 table, we would be able to maintain history of changes in address, while being able to distinguish the current address for each person. SCD 2 tables typically achieve this by adding Valid_From and Valid_To columns.
| First Name | Last Name | Street Address | Valid_From | Valid_To |
| John | Doe | 123 Sunset Blvd | 27-11-25 | null |
| Jane | Doe | 145 Princeton Cir | 27-01-25 | null |
| John | Doe | 873 Hickory St | 27-01-25 | 27-11-24 |
In the above example, we can see that John Doe changed address on 27-11-24, hence the entry for the '873 Hickory St' address has a Valid_To date. His new address, however, has a null Valid_To date, indicating that the '123 Sunset Blvd' address is his current address.
Building Snapshots (SCD 2 Tables) in dbt
If we were to try to build SCD 2 tables in SQL or Python, we might need to build convoluted logic to both maintain history while inserting new data. dbt, however, makes it extremely easy to build SCD 2 tables - or Snapshots. All it requires is a YAML file.
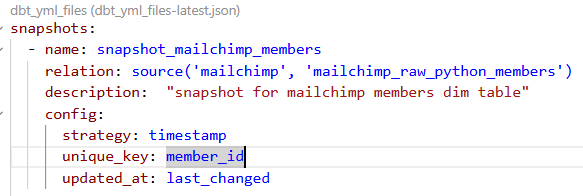
I built two snapshots for Mailchimp data. The Snapshot above was built for my members dimension table. Details for members will probably not change frequently, but I still wanted to preserve history when it does change while being able to add new members. Whenever details for a member changes, this Snapshot table will add a new row and update the Valid_To and Valid_From columns so that we'd be able to differentiate between historical and current records.
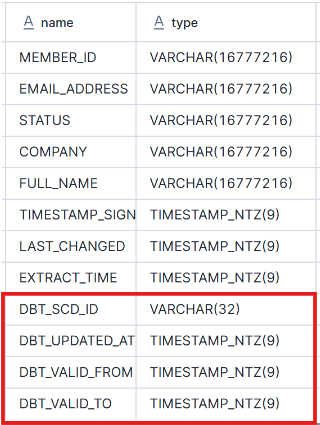
Above is what my schema for the members Snapshot looks like. dbt updates the four fields in red.
Building a Staging Table Based on a Snapshot
Now, we can build a staging table based on this Snapshot.
with source as (
select *
from {{ ref('snapshot_mailchimp_members') }}
where dbt_valid_to is null
)
Above, I built my members staging table by referencing the snapshot. To filter out old records, I used a where filter to only grab rows where dbt_valid_to is null, which indicates that the row is current.
We can build on this staging table to merge with fact tables based on date ranges, so that each entry in a fact table is merged with the record that was current at the time of events.
In short, dbt makes it extremely convenient to build SCD 2 tables and base downstream models on them. This allows you to maintain history and incrementally update downstream models.