


Before beginning any form of data analysis, it is important to ensure that the data is in good shape. In some instances, when you begin to prepare data it may become evident that the dataset is not complete.
First of all, what do we mean by complete data?
Whilst simplistic, this table would contain enough information to analyse the fruit sales and remaining stock for a fruit stall which only sold apples, strawberries, mangoes and oranges.
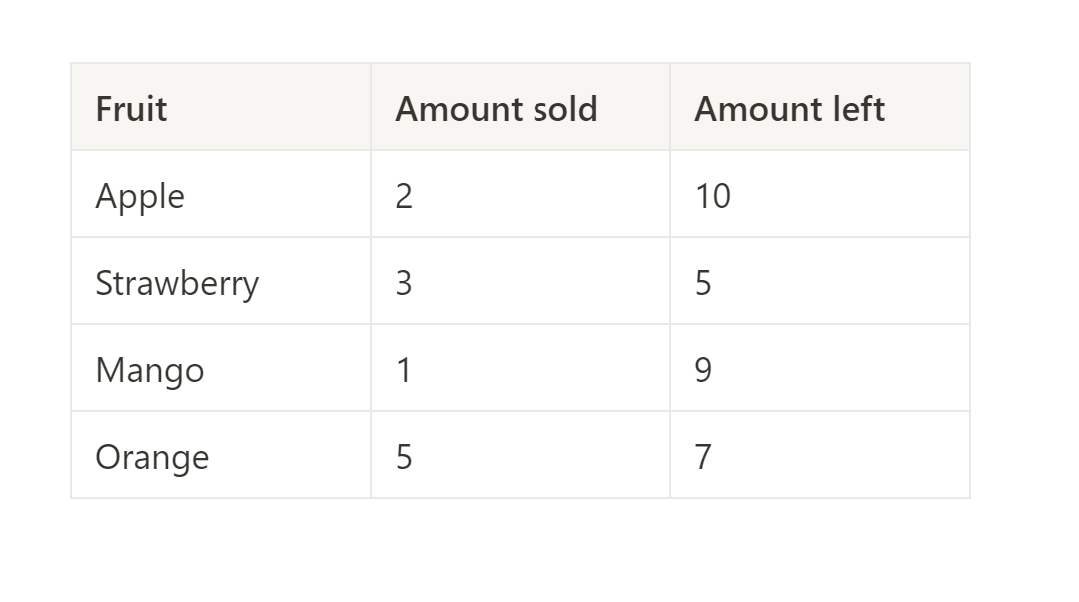
Now, if we were asked to analyse sales and stock data for the same fruit stall, but instead of Table 1, we received the following, we would no longer have what appears to be complete data.
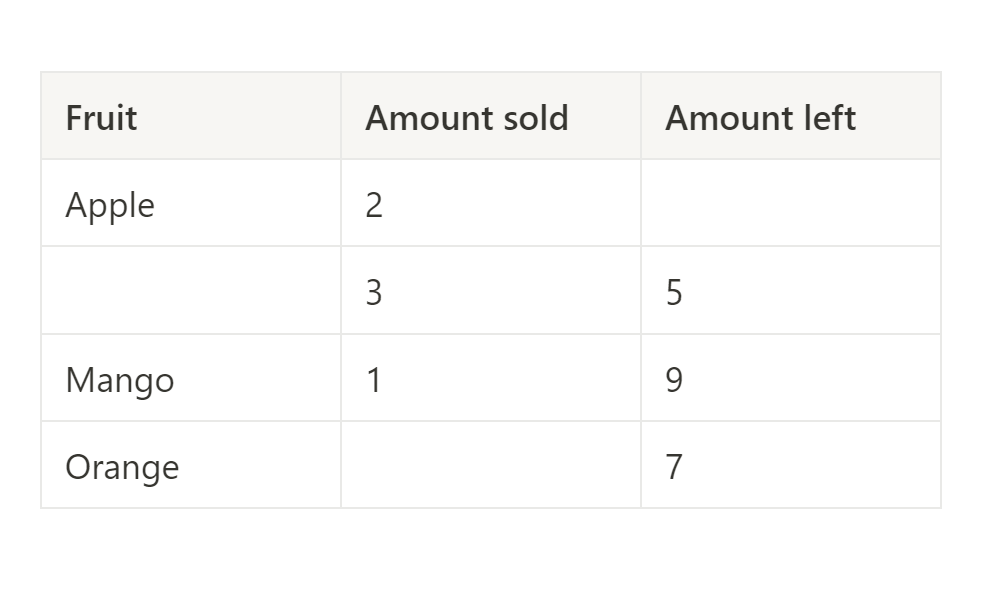
Working with this data table would require us to determine which of the blank fields are missing, and which are null.
Missing data tends to be information we would expect to see, which instead is blank. Null data on the other hand is information we may not expect to be there in the first place.
When presented with table 2, there are multiple assumptions you could make, and the only way to determine the ‘correct’ answer is by gathering more information on the data.
Scenario 1: In scenario one, we could assume that all blanks are missing data. This would mean that we should have three values which are not present. To try to remedy this, we could, for example, discuss our concerns with the data owner (in this case our friendly fruit stall owner) to determine what information should be in those fields and how we can acquire it.
Scenario 2: In scenario two, we could assume that all blanks are nulls. This is probably less likely than scenario 1, given that one of the missing fields is a type of fruit which has values for both amounts sold and amount left.
Scenario 3: In scenario three, we could assume that the entry in the fruit field is missing and that both the blank fields in the numeric data fields are nulls. This would mean that the null values under amount sold and amount left represent 0.
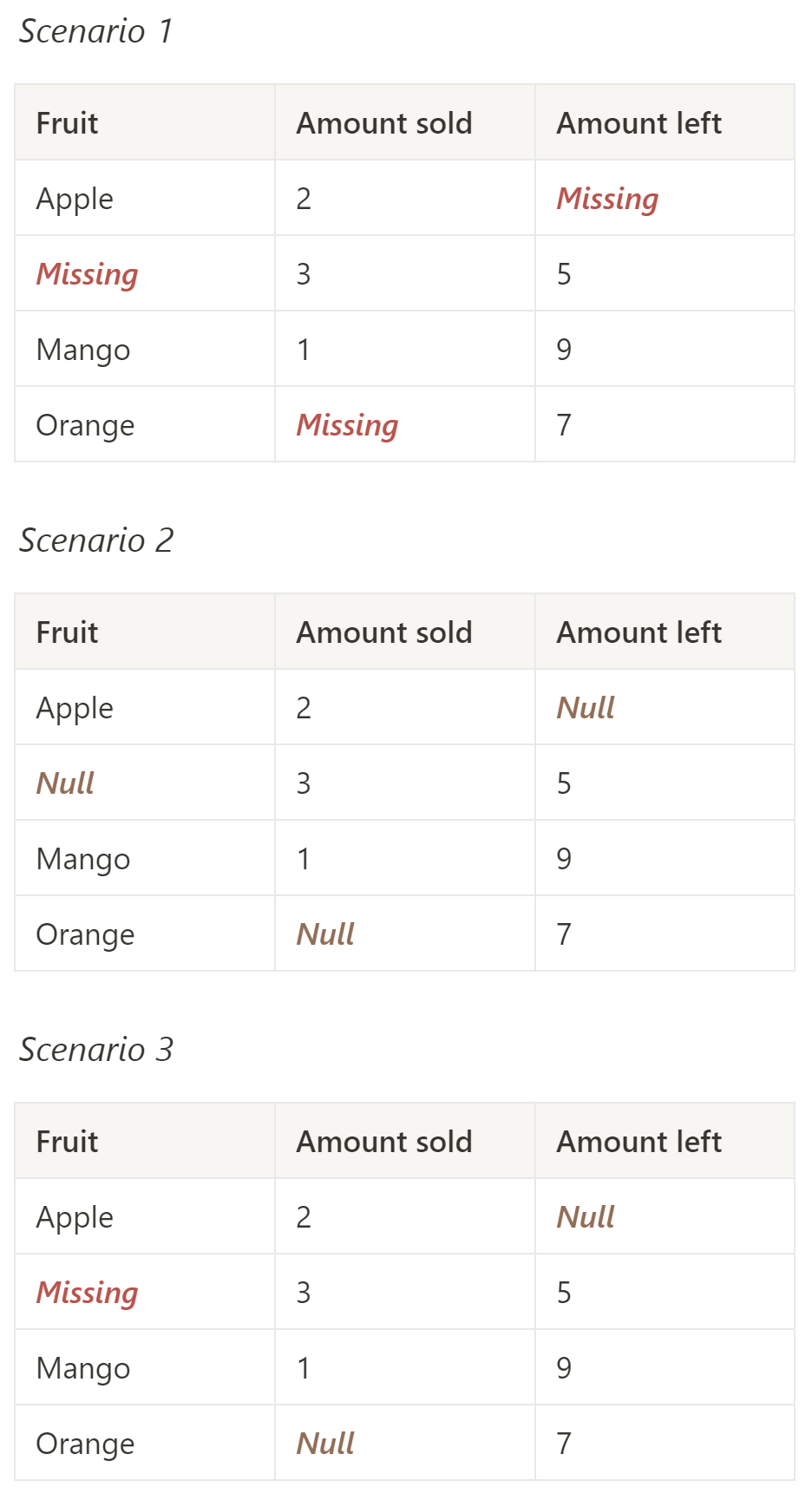
Ultimately, the decision on which scenario, if any, is right should be made with consideration of the wider context and by examining or consulting the source of the data. Following this, we would also need to consider why the data is missing and whether it can be sourced elsewhere.